-
Fall Recovery for Quadrupeds
Introduction Legged robots operating in real-world environments are inevitably exposed to disturbances, uneven terrain, and interaction forces that can lead to loss of balance and falls. Robust fall recovery is therefore a critical capability for enabling truly autonomous deployment of quadruped robots in unstructured settings. While traditional approaches rely on hand-crafted reflexes or carefully engineered Read more
-

Fall Recovery for Humanoid Robots
Introduction Humanoid robots are designed to operate in human-centered environments, where unexpected contacts, uneven terrain, and external disturbances frequently lead to loss of balance and falls. Reliable fall recovery is therefore a key capability for long-term autonomous operation and human–robot coexistence. Classical approaches rely on carefully engineered whole-body controllers and pre-defined get-up sequences, which are Read more
-
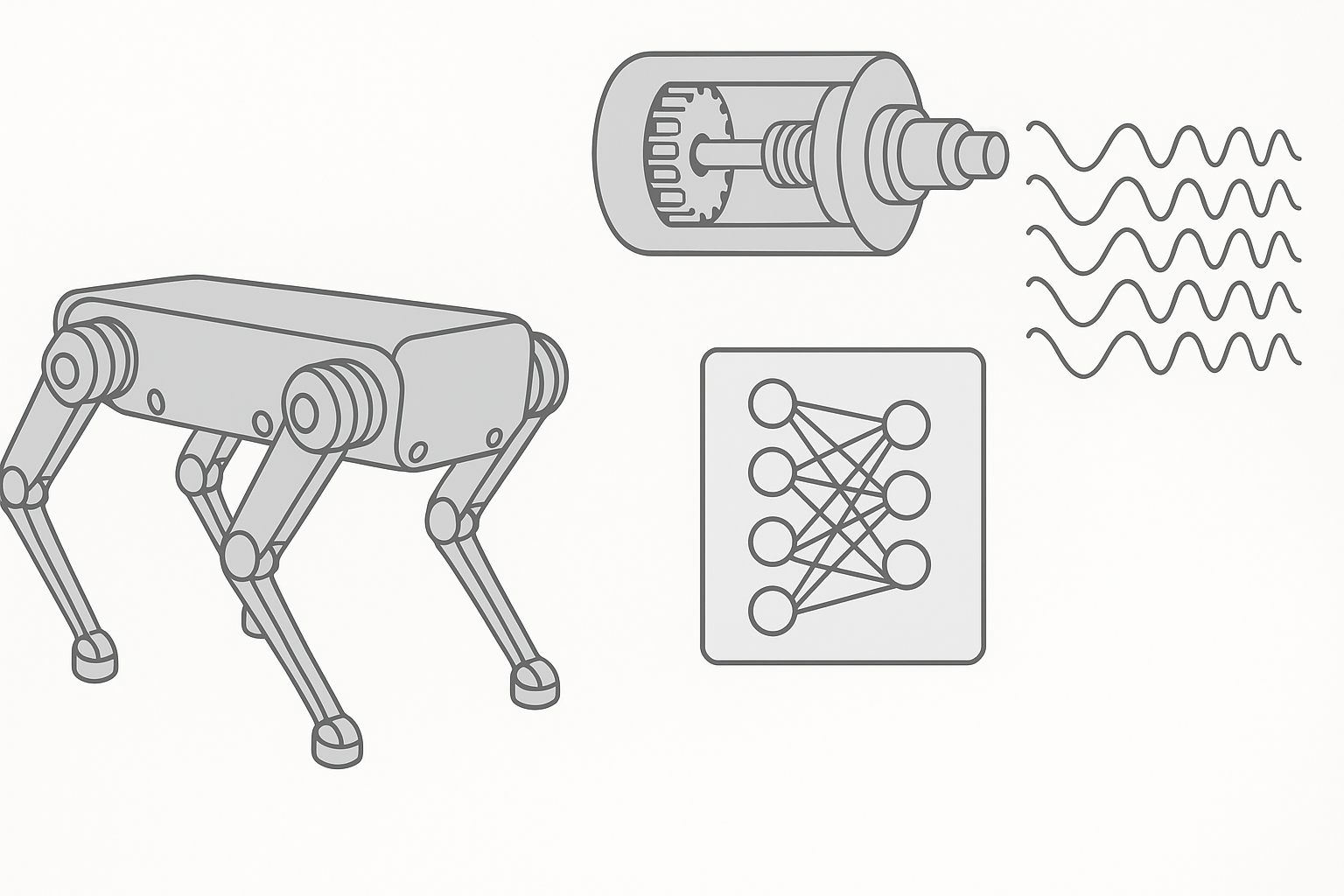
Actuator Modeling
Introduction Recent advances in GPU-based physics simulation and deep Reinforcement Learning (RL) have enabled the rapid training of control policies for complex, highly articulated robots such as quadrupeds and humanoids. Parallelized simulators now make it possible to obtain policies that transfer to hardware in a matter of minutes of simulated experience [1]. Despite this progress, Read more
-
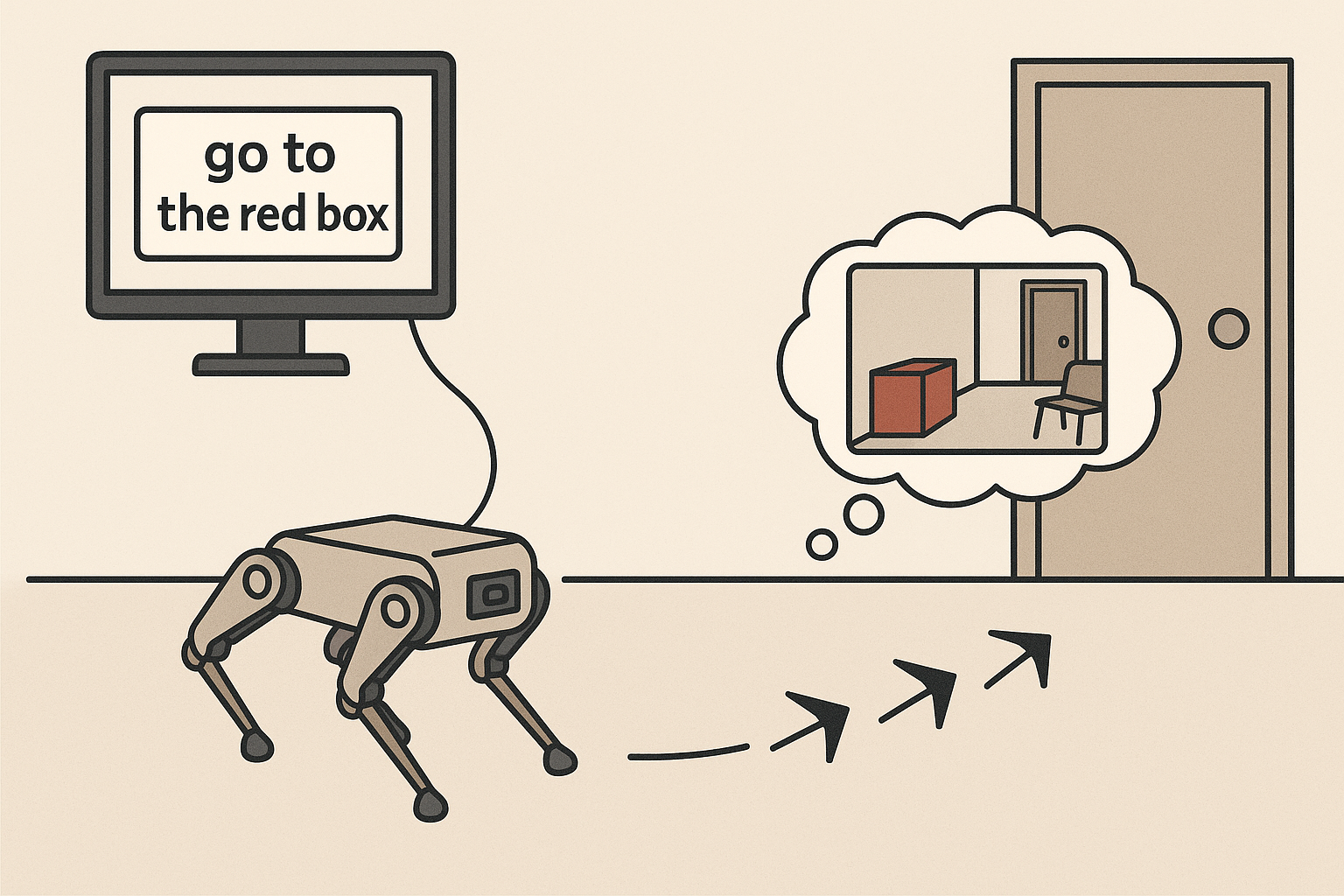
VLAs for Navigation
Introduction Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for grounding natural-language instructions in perception and control, enabling robots to execute high-level commands specified in human-friendly terms. In this project, we consider a navigation setting in which a mobile robot (Unitree GO2) receives an egocentric RGB-D observation together with a short natural-language instruction Read more
-

Quadruped Teleoperation System
Introduction Reinforcement Learning (RL) has recently enabled agile and dynamic behaviors in legged robots. However, RL alone is not always the most suitable tool, especially for sparse, long-horizon tasks that involve complex object manipulation. Even with careful problem formulation, reward design, and curriculum learning, such tasks can remain difficult to solve using standard RL methods. Read more