Background and motivation
Electron Cyclotron Resonance Heating (ECRH) systems inject high-power millimeter waves into magnetically confined plasmas to provide localized heating and, when needed, current drive. In tokamaks, the effectiveness and safety of ECRH depend strongly on how the beam propagates through an inhomogeneous, magnetized medium: refraction, mode evolution, and absorption determine the deposited power profile, while incomplete absorption can lead to reflected power and stray radiation that may stress plasma-facing components and diagnostic hardware. Reliable, fast beam-tracing simulations are therefore essential both for scenario design (choice of launcher angles, frequencies, polarization, and aiming) and for operational studies that require large parametric scans or near–real-time turnarounds.
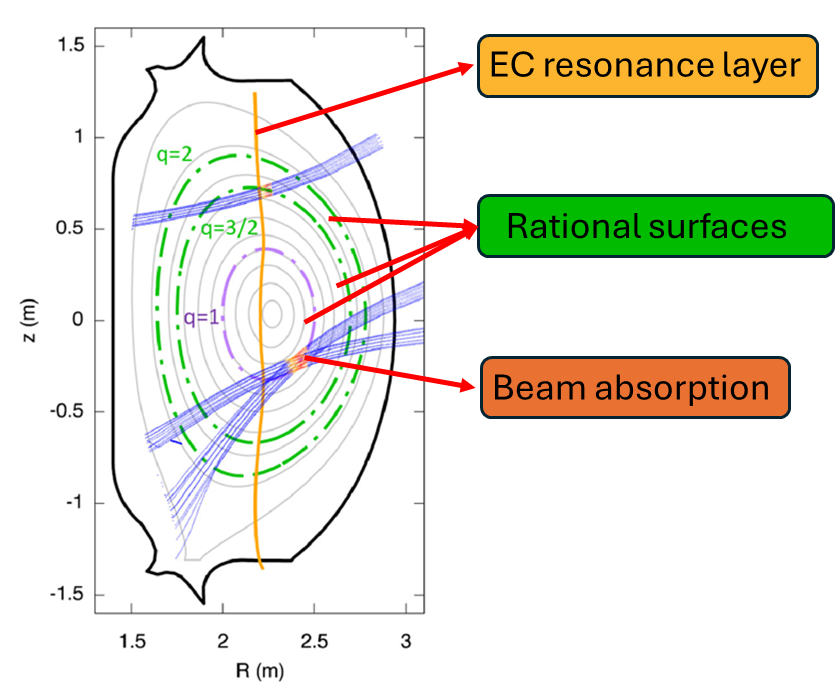
GRAY is a widely used beam-tracing tool for modeling microwave propagation and absorption in fusion plasmas. However, high-fidelity use cases—many rays per beam, multiple launchers, repeated runs across evolving plasma profiles, and reflection/recirculation effects—can make the computational cost a limiting factor. This thesis aims to improve GRAY’s performance and scalability while preserving physical consistency and numerical accuracy, enabling more extensive studies of absorbed vs. non-absorbed/reflected power and supporting workflows that need rapid repeated evaluations.
Overall objective
Develop and validate a performance-oriented redesign of GRAY focused on (i) algorithmic complexity understanding, (ii) software refactoring for clarity and maintainability, and (iii) parallel execution on modern hardware, so that multi-ray and multi-scenario simulations become significantly faster without degrading the quality of predicted absorption and stray-power-related metrics.
Specific goals
- Complexity study of the algorithm: characterize how runtime and memory scale with number of rays, integration steps, plasma grid resolution, and number of reflections/propagation segments.
- Functional analysis of the code: map the main computational kernels and data flows to identify bottlenecks (e.g., integration loop, field/profile interpolation, reflection handling, accumulation of deposited power).
- Architectural refactoring: split the numerical integration of ray/beam evolution from the reflection computation, producing clearer interfaces and preparing the code for thread-safe parallelism.
- Reflection/propagation redesign: define a recursive implementation used for reflection/propagation chains to reduce overhead and make execution more predictable and parallel-friendly.
- Stray radiation modeling: implement a new function for stray radiation diffusion, leveraging the above refactoring and adopting efficient data structures (e.g., hashmaps) to accelerate lookups/accumulations and reduce redundant work.
- Parallelization (shared memory): design and test parallel strategies for multi-ray simulations within the same beam (CPU multi-core), aiming for strong scaling when rays are independent or weakly coupled.
- Parallelization (distributed): extend to distributed multi-ray simulations across nodes (or across many beams/scenarios), enabling high-throughput parameter scans.
- Advanced acceleration tests: evaluate feasibility and performance of GPU offload and/or hybrid approaches, and test distributed execution using Open MPI or similar tools.
Methodology and work plan
The project will begin with reproducible benchmarks and profiling to establish a baseline and quantify bottlenecks. Next, a refactoring phase will separate integration from reflections and reorganize data ownership to minimize shared mutable state. The reflection/propagation logic will be revisited to reduce recursive overhead and enable batching where possible. A dedicated implementation for stray radiation diffusion will then be introduced, using efficient indexing/aggregation (hashmaps) consistent with the refactored structure. Finally, parallelization will be carried out in two layers: shared-memory parallelism for rays within a beam, and distributed parallelism for large ensembles of rays and scenarios. At each stage, regression tests and physics-based validation will ensure that predicted absorbed power profiles and non-absorbed/reflected contributions remain consistent with the baseline within defined tolerances.
Expected outcomes
- A faster, more scalable GRAY codebase capable of handling larger multi-ray and multi-scenario workloads.
- Clearer modular structure separating integration, reflection handling, and stray-radiation diffusion.
- Quantitative performance results (speedup, efficiency, strong/weak scaling) on CPU multi-core and distributed systems, with exploratory results on GPU/Open MPI configurations.
- A validation report demonstrating that performance improvements preserve accuracy in key outputs: deposited power distributions, absorption fractions, and indicators related to reflected/non-absorbed power and stray radiation.
This thesis will bridge physics-driven modeling needs and high-performance computing practices, directly supporting the design and analysis of ECRH systems for present and future thermonuclear fusion experiments.